Herein I describe some ideas for a new naming system to replace the Domain Name System (DNS) that has been in common use on the Internet for the past 25 years. Motivations for replacing the DNS are written on my DNS pages about Nimrod. More recently, with the US Department of Homeland Security "seizing" the domain names of groups accused of copyright violations, the dangers of a hierarchical design have been brought to the front of more people's minds.
A lot more time could be spent justifying a change to the Internet's
name system but for the moment I'm assuming that anyone who comes here
is already well familiar with those issues.
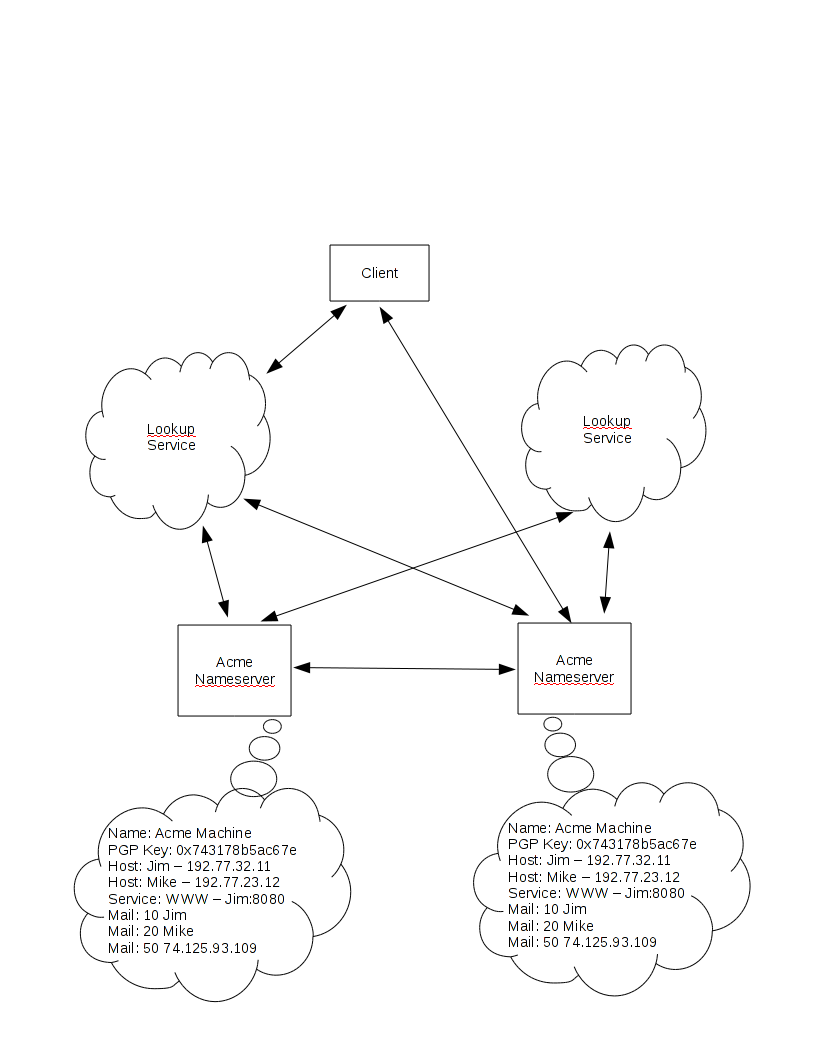
There are three levels to the architectural picture. At the top is a protocol that allows clients to make requests for database lookups. At the bottom is a protocol used to collect information from sites around the net to populate the databases for lookups. In between, there is room for several different and competing name services. Within itself, each of these name services may use whatever protocols and systems it wants. The primary difference from DNS at this point is the separation of the data from the name service which allows a practical means of setting up multiple name services.
As I am a fan of separating human friendly names from the keys used
to make lookups in the name database, we may then talk about an
additional layer above these basic three that comprise the heart of the
name system. This higher layer would take care of doing lookups
on human friendly names and returning the identifiers to be used as
keys into the name system. I imagine this to look much like the
web search engines with which we're well familiar these days.
So, to describe the system from the bottom up, we start with the
site's nameservers. These are conceptually owned and operated by
the network site itself. In practice, the site may well hire
someone else to handle this for them, much like many websites today
hire a DNS registrar to operate their DNS nameserver.
The nameservers hold the name data for a site: the name of the site,
the public PGP key for the nameserver, IP addresses for hosts at the
site, and so on. Think of it as the zone file from DNS though of
course we have the opportunity to greatly extend the types of data that
gets stored here.
These nameservers for a given site communicate amongst themselves to
keep its data synchronized.
The Lookup Services provide translation from a lookup key to the IP
addresses of the Nameservers for that site. Just what that key
is, is subject to some debate but I suggest something random chosen by
the site. Perhaps a public PGP key or a crypto-hash of some sort.
The lookup Service runs a web-crawler of sorts that searches through
the Internet, finding all the Nameservers out there and indexing them
by their keys. It also may be contacted by a Nameserver to either
notify it of the Nameserver's existence.
Internally, the Lookup Service no doubt is implemented as a large
number of cooperating servers that provide the necessary capacity,
redundancy, and reliability. The protocols necessary to deliver
on this service are outside the perview of this document.
A name system client starts off with the key to the site it wants to
talk to. It communicates with a Lookup Service, giving it that
key and receiving back the IP addresses of the site's Nameservers.
It then chooses a Nameserver and communicates directly with the site's
representative to ask for the database records it seeks.
It is recommended and expected that applications generally do not
expose this internal naming key to users but rather provide a user
interface on top that hides these details, using local names of some
sort suitable to the application.